You Are Probably Calling the Wrong Model for Most of Your Requests
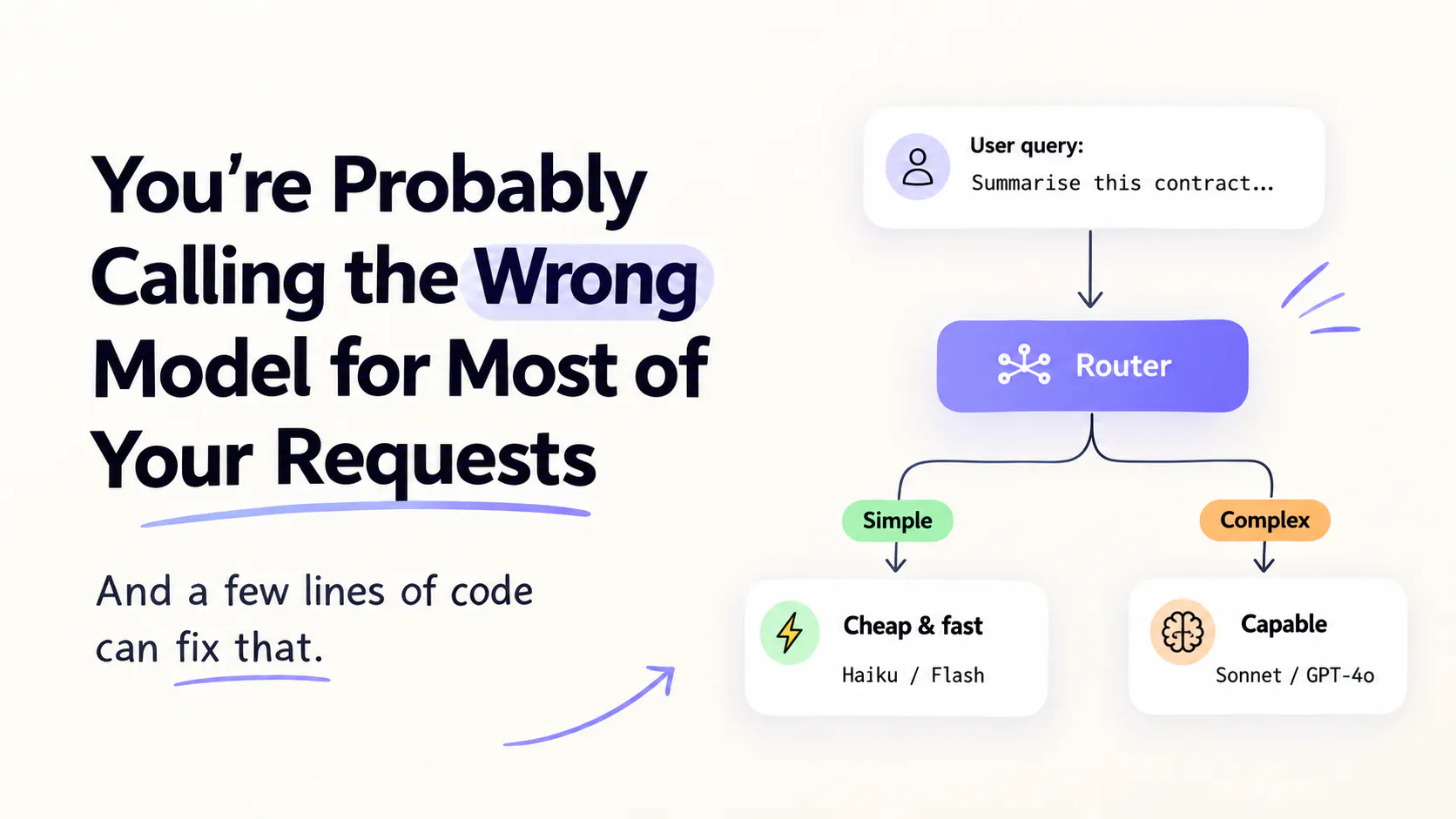
Here is something most LLM tutorials quietly ignore. Every request in your app gets sent to the same model, at the same cost, with the same latency. It does not matter if someone asks "what is the capital of France?" or "summarise this 40-page legal contract". Same model. Same price. Same wait.
That is not how you would design anything else in your stack. You would not spin up a GPU instance to serve a static HTML page. So why are we treating all LLM queries as equally complex?
The answer is usually that routing feels complicated. But it genuinely isn't. This article shows you a simple pattern that takes about 20 lines of Python to implement and can cut your API spend significantly while keeping quality where it matters.
The idea
Not all queries are equal. Some are simple lookups or rewrites that a small, fast, cheap model handles...
Copyright of this story solely belongs to hackernoon.com. To see the full text click HERE



