I Priced the Same Inference Workload on 4 GPU Clouds. Egress Was the Catch
A reproducible 2026 cost model across AWS, Azure, GCP, and a sovereign regional provider, and where the money actually goes.
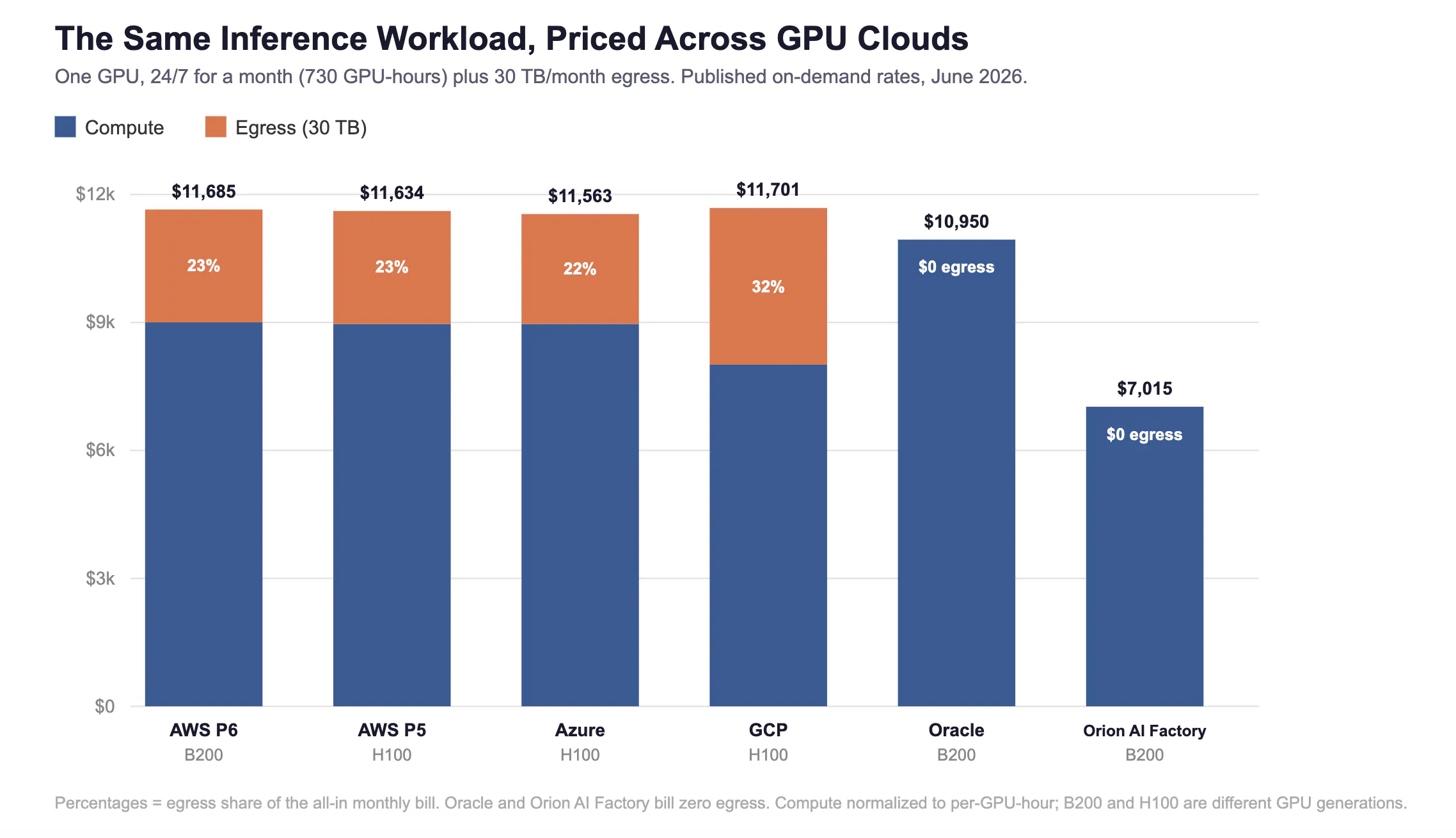
Every GPU cloud comparison I read stops at the same number: dollars per GPU-hour. It is the number on the pricing page, the number in the launch blog, the number people screenshot on X. And it is, at most, half of an inference bill.
The other half is the part nobody models. Data egress, plus a handful of network line items that never show up in the headline rate. On a workload that mostly trains in place, that half rounds to nothing. On a workload that serves, an inference API shipping tokens to users all day, it can be a third of what you pay, and it grows with every new user you celebrate.
So I built a model. One identical inference workload, priced across four GPU clouds using...
Copyright of this story solely belongs to hackernoon.com. To see the full text click HERE


